
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- visdom
- 로보틱스 입문
- RobotArm
- dynamixel
- mnist
- PUMA 560
- 6축 다관절
- boostcourse
- pytorch visdom
- NUCLEO board
- DeepLearning
- regression
- 파이토치로 시작하는 딥러닝 기초
- DH parameter
- 로보틱스입문
- Numpy
- 6자유도 로봇팔
- Python
- Introduction to Robotics: Mechanics and Control by John J Craig
- Robotics
- pytorch
- 파이토치
- custom cnn
- Pytorch로 시작하는 딥러닝 입문
- nucleo-f401re
- softmax
- IMU sensor
- 딥러닝
- 6dof
- Robot arm
- Today
- Total
슬.공.생
BoostCourse(DL)(week4)- MNIST and Convolutional Neural Network 본문
BoostCourse(DL)(week4)- MNIST and Convolutional Neural Network
AGT (goh9510@naver.com) 2022. 8. 16. 19:55합성곱 신경망 (CNN)의 사용 배경과 목적
일반적으로 다수의 층을 쌓아 신경망 구조를 구성하게 되는데 이때 해당 신경망으로 입력되는 정보는 다음과 같다.


Y 라는 손글씨(행렬 텐서)를 아래와 같이 (백터 텐서)변환하여 신경망 모델에 입력하게 되는데, 이때 행렬차원을 백터차원으로 변환하면서 행렬차원에서 얻을 수 있는 공간적인 구조(spatial structure)정보가 유실되게 된다.
이에 따라 위와같이 이미지등을 모델에 적용시키는 경우 입력정보의 유실이 좋지않은 결과를 가져올 수 있다.
- 스터디 피드백 결과 공간적인 구조(spatial structure)정보의 유실은 연산이나 컴퓨터 입장에서는 별다른 차이 없음
- 사용자나 설계자 입장에서 좀 더 구조, 과정에대한 파악이 용이하도록 하는데 관점이 있음
입력 data의 기본 구조
이미지 처리 과정에서 입력되는 이미지의 경우(높이, 너비, 채널) 이렇게 3가지의 값들로 구분되어지게 된다.
높이와 너비는 이미지의 세로, 가로 방향의 픽셀수를 의미한다.
마지막으로 채널은 색의 성분을 의미한다. 흑백의 경우 채널수는 1개(명암이)가 되며 컬러이미지의 경우는 3개(RGB)로 구분되어진다.
만약 일반 컬러이미지의 경우 세로가로28 픽셀이라면 (28x28x3)의 3차원 텐서로 이루어 집니다.
합성곱 연산의 과정
아래와 같이 입력 이미지Tensor의 값을 kernel 값으로 각 자리의 값을 서로 곱한것의 합으로 출력Tensor를 구성하게 되며 아래의 과정이 기본적인 합성곱 신경망의 연산 과정이다.
아래 과정에서는 stride라는 요소 또한 연산과정에 영향을 주는데, 'stride' 직역하면 '보폭' 을 뜻하고 kernel이 몇개 pixel만큼 이동하며 커널연산을 수행할지 결정하게 된다.



위의 과정에서는 입력단의 Tensor의 단위와 출력단의 Tensor의 단위가 매칭되지 않는다는 단점이 존재한다.
따라서 패딩(Padding) 과정을 통해 커널연산을 거치더라도 실제 입력 data와 출력 data의 Tensor의 형태를 동일하게 유지시킬 수 있다.
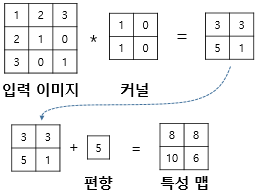


위 과정으로 합성곱 과정을 거치고 편향을 더하여 결과값으로 특성 맵을 얻게 된다. 입력 data의 형식, kernel의 크기, stride의 크기, padding의 크기 등을 통해 결과로 나오는 특성맵의 형식((Ow)x(Oh))이 결정되게 된다.
다수의 채널을 가지는 경우에는 input tensor가 채널의 크기만큼 커질 것이고 이에 따라 입력 Tensor가 2차원이 아닌 3차원 Tensor일 것이다. 만약 입력 data가 color image 이거나 다차원 Tensor일 경우에는 다음과 같이 합성곱 연산이 일어나게 된다.

입력이 3차원이라면 커널 또한 각 channel별로 나뉘어져 있으며 3차원의 형태를 띄게 된다. 하지만 특성맵의 경우 각 channel의 합성곱 연산값의 합이되며 1차원을 가지게 된다.
하나의 입력에서 하나의 커널을 통해 연산하여 특성맵을 얻어내는 과정과는 또 다르게 하나의 입력을 가지고 여러개의 커널을 통해 연산을 진행하는 방식 또한 존재한다. 이전과는 달리 특성 맵의 차원이 커널의 갯수와 일치하게 된다. 특성맵의 갯수가 커널의 갯수만큼 늘어나는 것이다.

.
합성곱 연산 이후에는 보통 풀링(Pooling)작업을 통해 특성맵의 크기를 작게 조절하는 과정을 거치게 된다.
Pooling 과정에는 이전의 합성곱 연산때 사용되는 kernel, stride의 부분들이 동일하게 존재한다.
Pooling은 두가지 형식이 있는데 한 kernel 내에서 최대값을 출력하는 MaxPooling, 평균값을 출력하는 AveragePooling,

합성곱 연산 진행
아래의 과정으로는 합성곱 모델의 층을 구성하고 직접 코드로 구현하는 과정이다.

class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
## input channel 1, output channel, kernel 수 32
nn.ReLU(), ## 활성화 함수
nn.MaxPool2d(kernel_size = 2, stride = 2) ## 특성맵 조절(maxpool)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=(2))
)
self.fc1 = nn.Linear(3*3*128, 625)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(625, 10, bias = True)
torch.nn.init.xavier_uniform_(self.fc1.weight)
torch.nn.init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
print(x.shape) ##torch.Size([100, 1, 28, 28])
out = self.layer1(x)
print(out.shape) ##torch.Size([100, 32, 14, 14])
out = self.layer2(out)
print(out.shape) ##torch.Size([100, 64, 7, 7])
out = self.layer3(out)
print(out.shape) ##torch.Size([100, 128, 3, 3])
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
return out위의 class의 내용과 같이 100개의 mini_batch로 이루어진 dataset이 (1채널 28*28) (32채널 14*14) (64채널 7*7) (128채널 3*3) 으로 합성곱과정을 거치게 되고 이후 view를 통해서 백터형태로 정리되게 된다.
정의한 CNN 모델을 통해 학습을 진행하는 코드는 아래와 같다.
비용함수는 CrossEntropy함수를, 최적화함수는 Adam을 사용한다.
model = CNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
##학습
model.train()
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y, in data_loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost/total_batch
print('[Epoch: {}] cost = {}'.format(epoch+1, avg_cost))
print('Learning complite')
model.eval()
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print("Accuracy:", accuracy.item())학습한 모델을 테스트하기 위해 MNISTtest data를 가져와 model에 입력시킨다.
argmax를 통해 가장 일치율이 높은 곳의 인덱스와 Y_test의 값과 비교하여 정확도를 계산하게 된다.
Visdom을 활용한 실시간 출력
import visdom
vis = visdom.Visdom()
vis.close(env="main")
'''
visdom을 import하고 기존의 visdom을 닫아준다
'''
def loss_tracker(loss_plot, loss_value, num):
'''num, loss_value, are Tensor'''
vis.line(X=num,
Y=loss_value,
win = loss_plot,
update='append'
)
'''
loss를 계속 업데이트하기 위해
vis.line을 이용
num로 data 별 인덱스를 전달
loss_value 로는 loss 값 전달
loss plot 이라는 윈도우에 append 방식으로 업데이트
'''
loss_plt = vis.line(Y = torch.Tensor(1).zero_(), opts = dict(title='loss_tracker',
legend = ['loss'],
showlegend = True ))
'''
값을 실시간으로 추가해주는 함수를 만들어준다.
plot을 하나 추가해준다.
'''##학습
model.train()
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y, in data_loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost/total_batch
print('[Epoch: {}] cost = {}'.format(epoch+1, avg_cost))
loss_tracker(loss_plt, torch.Tensor([avg_cost]), torch.Tensor([epoch]))
'''
cost의 평균값을
epoch에 맞춰서
loss_plt라는 plot에 전달한다.
'''
print('Learning complite')
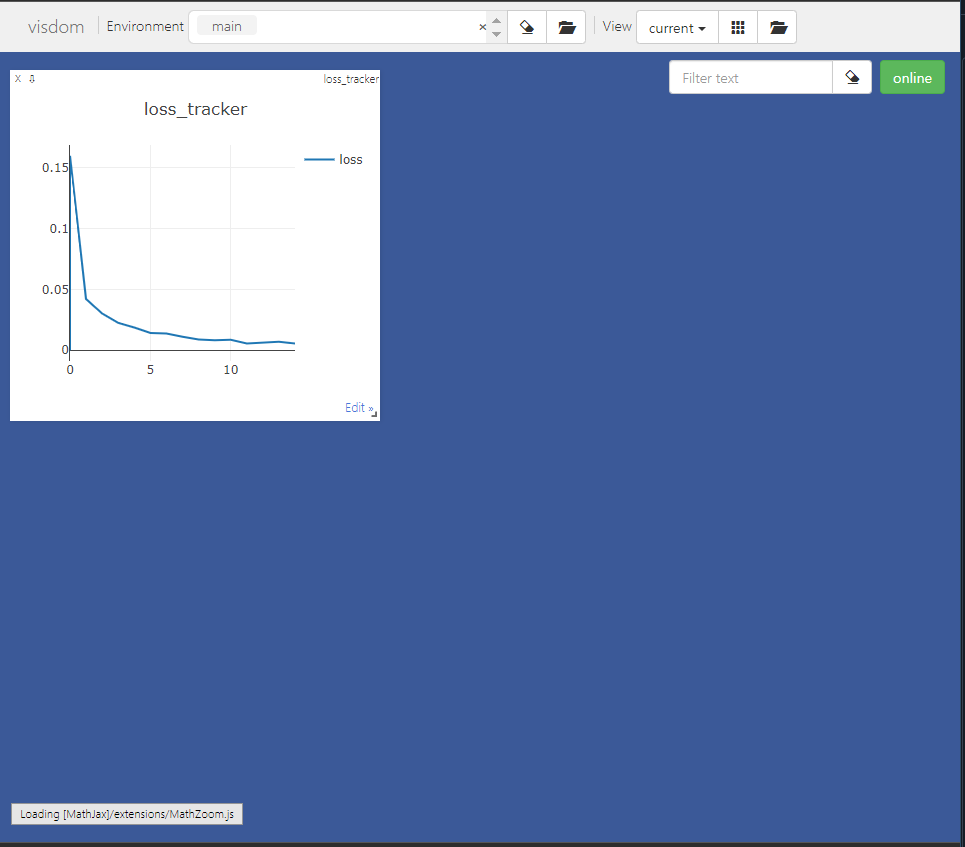
위와 같이 외부 시각화 방식을 통해 출력한 data는 다음과 같다.

'study > DeepLearning' 카테고리의 다른 글
| BoostCourse(DL)(week4)- CNN with Custom_Dataset (0) | 2022.08.17 |
|---|---|
| BoostCourse(DL)(week3)-BackPropagation (0) | 2022.08.10 |
| BoostCourse(DL)(week3)-Confusion Matrix (0) | 2022.08.09 |
| BoostCourse(DL)(week2)-Softmax Regression(MNIST) (0) | 2022.08.03 |
| BoostCourse(DL)(week2)-Softmax Regression_2 (0) | 2022.08.02 |



