
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- nucleo-f401re
- Pytorch로 시작하는 딥러닝 입문
- 파이토치로 시작하는 딥러닝 기초
- 파이토치
- Python
- Introduction to Robotics: Mechanics and Control by John J Craig
- 6자유도 로봇팔
- 딥러닝
- IMU sensor
- softmax
- PUMA 560
- RobotArm
- custom cnn
- Robot arm
- 6dof
- mnist
- pytorch
- 로보틱스 입문
- DH parameter
- pytorch visdom
- DeepLearning
- regression
- boostcourse
- dynamixel
- visdom
- NUCLEO board
- Robotics
- 로보틱스입문
- 6축 다관절
- Numpy
- Today
- Total
슬.공.생
BoostCourse(DL)(week2)-Softmax Regression(MNIST) 본문
BoostCourse(DL)(week2)-Softmax Regression(MNIST)
AGT (goh9510@naver.com) 2022. 8. 3. 14:23본 포스팅은 부스트 코스의 [ 파이토치로 시작하는 딥러닝 기초 ]와 [ Pytorch로 시작하는 딥러닝 입문 ]의 내용을 통해 학습한 내용입니다.
파이토치로 시작하는 딥러닝 기초
부스트코스 무료 강의
www.boostcourse.org
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
MNIST 란?
- MNIST는 우체국에서 편지의 우편번호등의 숫자 정보를 인식하기 위한 목적으로 만들어졌었던 훈련 데이터이다.
총 60000개의 훈련 데이터와 레이블 그리고 10000개의 테스트 데이터와 레이블로 구성되어있다.
레이블은 숫자별로 대응되어 (0~9) 10개로 구성되어있다.
- MNIST는 글씨가 적힌 숫자 이미지가 입력되면 그 숫자가 무슨 숫자인지 판단하는 일을 수행하게 된다.
MNIST 에 train data가 입력되는 방식은 다음과 같다.
- 이미지의 픽셀을 구분하여 벡터의 형태로 픽셀들을 정렬한다.
- 아래와 같은 경우 1 x 28 x 28 ==> 1 x 784
- ' 3 '에 대한 샘플 한개를 view를 통해 reshape 한다.
- 샘플 한개이기 때문에 (1 x 784) 의 벡터를 얻게 되며 일반적인 경우는 (batch_size x 784) 의 벡터를 얻게된다.
- .to('cuda')를 통해 GPU연산이 가능하도록 한다.
for X, Y in data_loader:
X = X.view(-1, 28*28).to('cuda')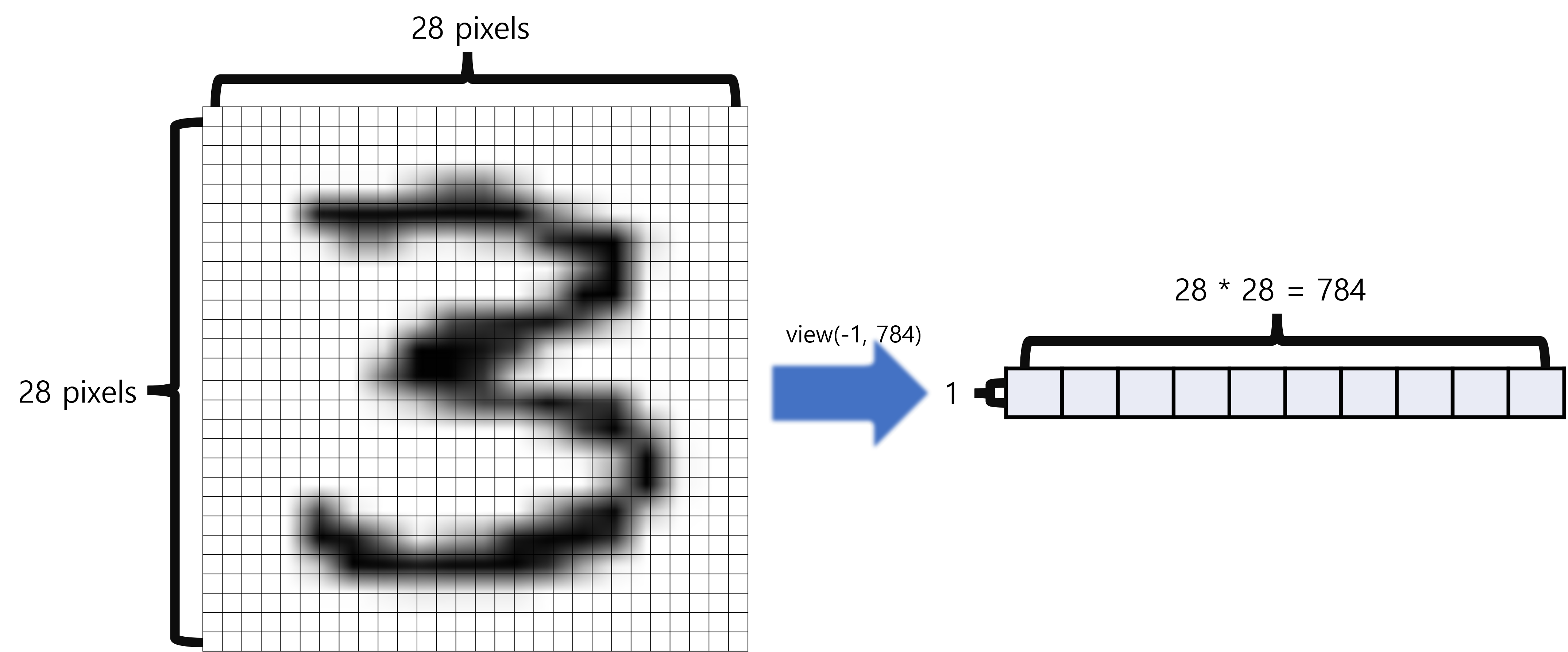
이미지를 다루는 과정이다 보니 torchvision이라는 툴을 추가해주게 된다.
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import random
이후 학습과 테스트에 사용할 dataset을 다음과 같이 내려받는다.
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)dset_MNIST()의 네가지 인자는 다음과 같다.
- root는 data를 내려받는 경로를 지정하는 인자이다.
- 학습용 data를 받는경우는 True, 테스트 용도의 경우는 False 이다.
- data를 받고 Tensor형태로 저장하겠다는 뜻이다.
- data가 없을 시 재 다운로드를 실시한다는 뜻이다.
dataset을 내려받은 뒤 DataLoader를 통해 학습전 세부 설정을 진행한다.
# dataset loader
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size, # 배치 크기는 100
shuffle=True,
drop_last=True)마찬가지로 DataLoader의 네가지 인자는 다음과 같다.
- 학습을 위해 가져올 data를 지정한다.
- batch_size를 지정한다.
- epoch 마다 batch_size로서 지정된 minibatch의 순서를 섞을지 결정한다.
- 지정한 batch size로서 dataset이 깔끔하게 나눠지지 않을시에 학습에 중복반영되는 요소가 없도록 나머지 버림을 결정한다.
data의 처리까지 완료했으니 이후 model을 정의한다.
softmax의 경우 입력되는 data가 많고 one-hot encoding을 통해 여러 class중 한가지로 분류되기에 다중 입출력 구조이다.
따라서 모델은 다음과 같다. (784 pixel 입력, 10개의 class)
# MNIST data image of shape 28 * 28 = 784
linear = nn.Linear(784, 10, bias=True).to('cuda')
이후 cross_entropy 함수를 통해서 cost를 계산하며 학습하는 과정을 진행합니다.
for epoch in range(training_epochs): # 앞서 training_epochs의 값은 15로 지정함.
avg_cost = 0
total_batch = len(data_loader)
for X, Y in data_loader:
# 배치 크기가 100이므로 아래의 연산에서 X는 (100, 784)의 텐서가 된다.
X = X.view(-1, 28 * 28).to(device)
# 레이블은 원-핫 인코딩이 된 상태가 아니라 0 ~ 9의 정수.
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
# 테스트 데이터를 사용하여 모델을 테스트한다.
with torch.no_grad(): # torch.no_grad()를 하면 gradient 계산을 수행하지 않는다.
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = linear(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
# MNIST 테스트 데이터에서 무작위로 하나를 뽑아서 예측을 해본다
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = linear(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
plt.imshow(mnist_test.test_data[r:r + 1].view(28, 28), cmap='Greys', interpolation='nearest')
plt.show()
'study > DeepLearning' 카테고리의 다른 글
| BoostCourse(DL)(week3)-BackPropagation (0) | 2022.08.10 |
|---|---|
| BoostCourse(DL)(week3)-Confusion Matrix (0) | 2022.08.09 |
| BoostCourse(DL)(week2)-Softmax Regression_2 (0) | 2022.08.02 |
| BoostCourse(DL)(week2)-Softmax Regression_1 (0) | 2022.08.02 |
| BoostCourse(DL)(week2)-Sequential model(class) (0) | 2022.08.01 |



