
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 파이토치로 시작하는 딥러닝 기초
- Python
- boostcourse
- Pytorch로 시작하는 딥러닝 입문
- 파이토치
- RobotArm
- NUCLEO board
- Robot arm
- regression
- 6자유도 로봇팔
- pytorch
- 로보틱스입문
- custom cnn
- mnist
- Numpy
- 6축 다관절
- PUMA 560
- DeepLearning
- softmax
- DH parameter
- 로보틱스 입문
- Introduction to Robotics: Mechanics and Control by John J Craig
- IMU sensor
- Robotics
- pytorch visdom
- dynamixel
- nucleo-f401re
- visdom
- 6dof
- 딥러닝
- Today
- Total
슬.공.생
BoostCourse(DL)(week2)-Softmax Regression_2 본문
BoostCourse(DL)(week2)-Softmax Regression_2
AGT (goh9510@naver.com) 2022. 8. 2. 18:00본 포스팅은 부스트 코스의 [ 파이토치로 시작하는 딥러닝 기초 ]와 [ Pytorch로 시작하는 딥러닝 입문 ]의 내용을 통해 학습한 내용입니다.
파이토치로 시작하는 딥러닝 기초
부스트코스 무료 강의
www.boostcourse.org
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
Softmax Regression 이전 Logistic Regression의 경우 아래와 같이 진행된다.
Linear, Sigmoid 함수를 통해 실제값 0, 1 사이의 값을 만들어내고 이를 통해 오차(0.75)를 산출해 내고 임계값(0.5)을 설정하여 참과 거짓 등의 이진화 분류를 진행하게 된다.
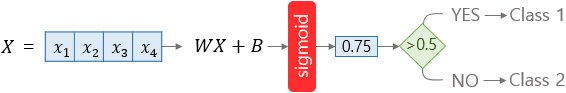
Softmax Regression의 경우는 아래와 같다.
샘플 한 개를 기준으로 한번 회귀를 진행하게 되면 해당 데이터 샘플이 어떤 클래스에 가장 적합한지 백분율로써 예측값을 출력하게 된다.

백분율로써 오차(출력) 값을 출력하기 때문에 아래의 식과 같이 확률이 계산된다.
확률 계산은 출력의 개수(선택지) 만큼 반복되고 선택지가 3개일 경우 확률(p)이 3개 계산된다.


그림으로 회귀 과정을 나타내면 다음과 같다.
입력 data들을 통해 각 class(선택지)의 예측값을 계산하고 실제값과 비교하여 산출된 오차를 통해 W와 b를 업데이트하게 된다.

오차를 산출하는 것까지의 과정을 행렬 연산으로 나타내면 다음과 같다.
아래의 경우는 5개의 샘플, 4개의 항목으로 입력 data를 구성하였고 3개의 클래스로 구분될 수 있도록 하였다.
따라서
- x의 경우 5행(샘플), 4열(항목) ==> 5x4 행렬
- W의 경우 4행(항목 별 weight), 3열(구분할 class 수) ==> 4x3 행렬
- b의 경우 5행(샘플), 3열(구분할 class 수) ==>5x3 행렬
- y(예측값)의 경우 5행(샘플 수), 3열(class 수) ==>5x3 행렬
와 같이 정리된다.

예측값을 구한 후에는 Costfunction을 구성한다.
소프트 맥스 회귀에서는 costfunction으로 cross-entropy functions을 사용하는데 아래와 같이 구성된다.

위의 식에서 y는 실제값, k는 분류할 클래스의 갯수, y_(j)는 실제값의 원-핫 벡터의 j번째 인덱스의 값을 의미한다.
p_(j)는 샘플데이터가 j번째 클래스일 확률을 나타낸다.
x중 샘플하나가 계산되는 과정을 예로 든다면
- 실제값의 원-핫 벡터값에서 1을 가지는 원소의 인덱스가 c라고 한다면
- p_(c)는 1이며 실제값 y또한 1이다
- 위의 식에 의해 -1*log(1) = 0
- 예측값이 실제값과 정확히 일치하였음으로 cost 값은 0이된다.
위의 과정에서 실제값이 1인 경우, cost가 존재했지만 실제값이 0인 경우 cost 값 자체를 알수 없는 형태이다.
'study > DeepLearning' 카테고리의 다른 글
| BoostCourse(DL)(week3)-Confusion Matrix (0) | 2022.08.09 |
|---|---|
| BoostCourse(DL)(week2)-Softmax Regression(MNIST) (0) | 2022.08.03 |
| BoostCourse(DL)(week2)-Softmax Regression_1 (0) | 2022.08.02 |
| BoostCourse(DL)(week2)-Sequential model(class) (0) | 2022.08.01 |
| BoostCourse(DL)(week2)-Logistic Regression (0) | 2022.08.01 |



